
Federe Öğrenme: Veri Gizliliği ve Etik Sorunlar
İçindekiler
- Özet
- Giriş
- Federated Learning Kavramı
- Federated Learning Nedir?
- Çalışma Mantığı
- Klasik Merkezi Sistemlerden Farkı
- Kullanım Alanları
- Federated Learning Sistemlerinde Etik Problemler
- Veri Gizliliği ve Mahremiyet Problemleri
- Gradient Leakage (Dolaylı Veri Sızıntısı)
- Data Poisoning (Veri Zehirleme) Saldırıları
- Güvenilirlik ve Model Manipülasyonu
- Adalet ve Şeffaflık Problemleri
- Etik Problemlere Yönelik Çözüm Yaklaşımları
- Secure Aggregation (Güvenli Toplama)
- Differential Privacy (Diferansiyel Gizlilik)
- Güven Skoru ve Anomali Tespiti
- Güvenlik ve Gizlilik Arasındaki Denge
- Örnek Uygulama: Geliştirilen Web Tabanlı Simülasyon Sistemi
- Sistemin Amacı
- Admin Paneli Yapısı
- Client Yapısı
- Data Poisoning Simülasyonu
- Güvenli Toplama Mekanizmasının Simülasyonu
- Bulgular ve Değerlendirme
- Saldırı Durumunda Model Davranışı
- Güvenli Toplama Sonrası Sonuçlar
- Etik Açıdan Genel Değerlendirme
- Sonuç
- Kısaca Özet
- Kaynakça
1.Özet
Bu çalışma, günümüzde veri gizliliğini korumak için geliştirilen Federe Öğrenme (Federated Learning) sistemlerini ve bu sistemlerin beraberinde getirdiği etik sorunları incelemektedir. Klasik merkezi sistemlerin aksine veriyi cihazda tutan bu yöntem, mahremiyet açısından büyük bir avantaj sunsa da (McMahan ve ark., 2017), verinin içeriğinin denetlenememesi nedeniyle “veri zehirlenmesi” (data poisoning) gibi saldırılara açık hale gelmektedir (Bhagoji ve ark., 2019). Çalışma kapsamında, bu tartışmalı durumu görselleştirmek amacıyla bir web simülasyonu geliştirilmiştir. Yapılan deneyler sonucunda, gizlilikten ödün vermeden güven skoru ve anomali tespiti gibi yöntemlerle sistem güvenilirliğinin korunabileceği saptanmıştır.
2.Giriş
Yapay zekayı eğitmek için veri toplamak büyük bir gizlilik krizi oldu. Federe Öğrenme veriyi merkezi sunucuya hapsetmek yerine cihazda bırakıyor. Bu sayede kullanıcı mahremiyeti korunuyor. Ama bence asıl hikaye burada başlıyor. Sistem gizliliği merkeze alınca sunucu gelen bilgiyi denetleyemiyor. Bu durum aslında ciddi bir etik boşluk yaratıyor. Kötü niyetli kişiler sisteme sızıp yapay zekayı “zehirleyebiliyor”. Yani gizliliği korurken sistemin dürüstlüğü tehlikeye giriyor.
Çalışmamda bu gizlilik ve güvenilirlik çatışmasını somutlaştırmak istedim. Geliştirdiğim web simülasyonunda saldırganların modeli nasıl yıktığını görüyoruz. Ama sadece kötü tarafı değil, çözümü de gösterdim. “Güvenli Birleştirme” gibi yöntemlerin nasıl kalkan olduğunu izleyebiliyoruz. Yapay zeka etiği genelde makalelerde ve teoride kalıyor. Bu projenin en değerli tarafı interaktif bir uygulama olmasıdır. Kullanıcı mahremiyetinden vazgeçmeden güvenli bir sistem kurulabileceğini kanıtladım. Bu bakış açısının gelecek tasarımlar için önemli bir referans olacağını düşünüyorum.
3.Federated Learning (Dağıtık Öğrenme) Kavramı
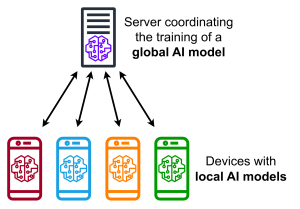
Şekil 1: Merkezi Federe Öğrenme Protokolü. Kaynak: Wikimedia Commons. CC BY-SA 4.0 ile lisanslanmıştır. (MarcT0K,2023)
3.1 Federated Learning Nedir?
Aslında Federe Öğrenme’yi en basit haliyle şöyle düşünebiliriz: Yapay zekayı eğitmek için verileri bir merkeze toplamak yerine, eğitimi verinin ayağına götürmek. Geleneksel yöntemlerde her şeyimizi bir sunucuya yüklememiz gerekirken, bu yöntemde veri cihazımızdan dışarı adımını bile atmıyor. Sunucuya giden tek şey, cihazın yerel olarak öğrendiği o küçük “bilgi özetleri” oluyor.
3.2 Çalışma Mantığı
Sistem bence çok mantıklı bir döngüyle ilerliyor. Önce merkez sunucu elindeki ana modeli tüm cihazlara dağıtıyor. Sonra her cihaz, içindeki o özel verilerle bu modeli bir güzel eğitiyor ve ortaya çıkan küçük güncellemeleri (gradyanları) merkeze geri yolluyor. Sunucu da binlerce cihazdan gelen bu parçaları toplayıp “ortalama” bir hesapla ana modeli güncelliyor. Bu döngü sürekli devam ettikçe yapay zeka da her seferinde biraz daha akıllanıyor.
3.3 Klasik Merkezi Sistemlerden Farkı
Klasik sistemlerin gerçekten büyük bir sıkıntısı vardı. Örneğin bütün fotoğraflarımızı veya sağlık kayıtlarımızı devasa bir bulut deposuna yüklemek zorundaydık. Bu nedenle hem veri trafiği artıyordu hem de ciddi bir güvenlik riski oluşuyordu. Oysa Federe Öğrenme’de veri asla merkezileşmiyor. Böylece hem internet paketimizden tasarruf ediyoruz hem de özel hayatımızı daha iyi koruyoruz. Kısacası durumu şöyle özetleyebilirim. Klasik sistemde “veri merkeze gider” ama bu yeni sistemde “model veriye gider”. Sonuç olarak bu değişimin dijital güvenlik için devrim niteliğinde olduğunu düşünüyorum.
3.4 Kullanım Alanları
Bu yöntem özellikle mahremiyetin çok kritik olduğu yerlerde karşımıza çıkıyor:
Akıllı Telefonlar, Klavyelerimizdeki bir sonraki kelime bu sayede mesajlarımızı okumadan öğrenir.
Sağlık, Farklı hastanelerdeki hasta kayıtları gizli tutularak, kanser teşhisi yapan yapay zekalar ortaklaşa eğitilebilir.
Finans: Bankalar, müşteri verilerini paylaşmadan dolandırıcılık tespit sistemlerini birlikte geliştirebilirler.
4.Federated Learning Sistemlerinde Etik Sorunlar
4.1 Veri Gizliliği ve Mahremiyet Problemleri
Aslında bu sistemin asıl vaadi gizliliği korumak ama dürüst olmak gerekirse, kağıt üzerindeki her şey her zaman pratikte kusursuz işlemiyor. Veriler cihazımızdan hiç çıkmasa bile, sunucuya yolladığımız o model özetleri üzerinden kişisel bilgilerimizin izinin sürülebilme riski bence hala masada duruyor. Bu durum, “Verilerim gerçekten güvende mi?” sorusunu sordururken, sistemin etik güvenilirliği hakkında da kafalarda soru işareti bırakıyor.
4.2 Gradient Leakage (Dolaylı Veri Sızıntısı)
İşte işin teknik ve bence biraz da ürkütücü kısmı burası. Cihazımızdan çıkan “gradyan” dediğimiz o matematiksel güncellemeler, aslında ham verimizin bir nevi dijital parmak izini taşıyor. Gerçekten zeki saldırganlar veya kötü niyetli bir sunucu yöneticisi, sadece bu gradyanlara bakarak bizim özel fotoğraflarımızı veya yazdığımız metinleri sanki bir yapbozu birleştirir gibi geri dönüştürebiliyor. Yani veri içeride kalsa bile, “gölgesi” üzerinden aslına ulaşılabiliyor olması ciddi bir mahremiyet açığı.
4.3 Data Poisoning (Veri Zehirleme) Saldırıları
Ayrıca bu sorun projemin ve web uygulamasının tam merkezinde yer alıyor. Çünkü sunucu gizlilik gereği veriyi asla göremiyor. Bu nedenle sisteme dahil olan herkesi dürüst kabul etmek zorunda kalıyor. Fakat bence asıl tehlike tam olarak burada başlıyor. Örneğin kötü niyetli bir kullanıcı modele bilerek yanlış eğitim verileri yollayabilir. Spam mesajlarını normalmiş gibi göstererek yapay zekayı “zehirleyebilir”. Sonuç olarak sistemin denetlenemez olması büyük bir etik boşluk yaratıyor.
4.4 Güvenilirlik ve Model Manipülasyonu
Zehirlenme saldırıları doğrudan modelin güvenilirliğini yerle bir ediyor. Yapay zeka, bu yanlış yönlendirmeler yüzünden hatalı kararlar vermeye başlarsa, sisteme duyulan o temel güven de sarsılıyor. Bir yapay zekanın manipüle edilerek kitleleri yanıltacak sonuçlar üretmesi, bilişim etiği açısından bence kabul edilemez bir durum.
4.5 Adalet ve Şeffaflık Problemleri
Dağıtık sistemlerde bazen model, sadece belirli grupların verilerine daha fazla odaklanabiliyor. Bu da sistemin bazı kullanıcılar için harika çalışırken, diğerleri için (örneğin farklı bir aksanla konuşanlar veya azınlık gruplar) hatalı sonuçlar vermesine, yani dijital bir ayrımcılığa yol açabiliyor. Ayrıca sistemin mutfağında kararların tam olarak nasıl alındığını göremememiz, şeffaflık ilkesini de ciddi şekilde zedeliyor.
5.Problemlere Yönelik Çözüm Yaklaşımları
5.1 Secure Aggregation (Güvenli Toplama)
Sunucunun bilgileri görmesini engelleyen harika bir yöntem var. Güvenli Toplama sayesinde kimin ne gönderdiği matematiksel olarak gizleniyor. Sunucu sadece bütün cihazlardan gelen verilerin toplamını görebiliyor. Mahremiyet için bu yöntem gerçekten çok güçlü bir çözüm. Ancak bence bu durumun ciddi bir yan etkisi var. Sunucu “zehirli” veri gönderen kişiyi asla ayırt edemiyor. Bu da güvenlikte büyük bir zayıflık oluşturuyor.
5.2 Differential Privacy (Diferansiyel Gizlilik)
Diğer bir yaklaşım ise cihazlardan çıkan verilere kasıtlı olarak “gürültü” dediğimiz küçük rastgele hataların eklenmesi. Bu gürültü, bireysel verilerin kesin olarak analiz edilmesini zorlaştırarak gradient leakage (dolaylı sızıntı) gibi riskleri önlemeyi amaçlıyor. Etik açıdan baktığımda bu durumu, kullanıcının kimliğini matematiksel bir sis bulutu arkasına saklayan çok güçlü bir kalkan olarak görüyorum.
5.3 Güven Skoru ve Anomali Tespiti
İşte burası benim yaptığım çalışmanın asıl kilit noktası. Sisteme katılan cihazların dürüst olup olmadığını anlamak için her birine bir “Güven Skoru” atıyoruz. Eğer bir cihaz, diğer kullanıcıların genel eğiliminden çok farklı ve şüpheli veriler yolluyorsa, sistem bunu hemen bir “anomali” yani sapma olarak algılıyor. Bu sayede, verinin içeriğine hiç bakmadan sadece bu istatistiksel sapmaları takip ederek kötü niyetli kişileri ağdan dışlamak mümkün hale geliyor.
5.4 Güvenlik ve Gizlilik Arasındaki Denge
Bana kalırsa Federe Öğrenme dünyasındaki asıl etik savaş bu hassas denge üzerinde kurulmalı. Gizliliği çok artırırsak saldırganları göremez hale geliyoruz, güvenliği çok artırırsak da bu sefer kullanıcı mahremiyetini bozma riskimiz doğuyor. Bence ideal olan, her iki tarafın da haklarını koruyabilen, yani veriyi doğrudan görmeden sistemin dürüstlüğünü denetleyebilen hibrit algoritmalar üzerine yoğunlaşmak.
6. Örnek Uygulama: Geliştirilen Web Tabanlı Simülasyon Sistemi
6.1 Sistemin Amacı
Simülasyonu tasarlarken asıl hedefim bu kavgayı canlı göstermekti. “Gizlilik mi, güvenlik mi?” sorusunu kağıt üzerinde bırakmadım. Karmaşık algoritmalar kötü niyetli verilerle kolayca manipüle edilebiliyor. Bu durum modelin başarısını bir anda aşağı çekiyor. Bunu herkesin görebileceği bir şekilde görselleştirmek istedim. Teorik sorunları somut uygulama üzerinden izlemek çok önemli. Bence bu yöntem konunun etik boyutunu anlamayı kolaylaştırıyor.
6.2 Sistem Mimarisi Uygulama:
Uygulamayı kurgularken, merkezi bir yönetici paneli (Admin Paneli) ve ona bağlı çok sayıda kullanıcıdan (Client) oluşan bir yapı kurdum. Burada veri gizliliği kırmızı çizgim olduğu için istemci cihazlardaki mesajların içeriğini asla sunucuya taşımıyorum. Bunun yerine, sistem sadece yerelde eğitilen modelden çıkan güven skorlarını ve o meşhur “gradyan” bilgilerini Firebase üzerinden merkeze iletiyor. Böylece verinin mahremiyetine dokunmadan, modelin kolektif bir şekilde nasıl geliştiğini ya da manipüle edildiğini takip edebiliyoruz.

Şekil 2: Federated Learning Web Sitesi Giriş Arayüzü
6.3 İstemci (Client) Yapısı
İstemci tarafı, kullanıcıların sisteme katıldığı mobil uyumlu bir arayüzdür. Kullanıcılar kendilerine gelen mesajları “Spam” veya “Normal” olarak sınıflandırarak yerel eğitimi gerçekleştirirler. Bu süreçte her kullanıcının yaptığı işlemlere göre sistem tarafından bir güven skoru tutulur.
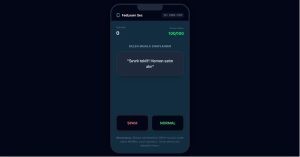
Şekil 3: Federated Learning Web Sitesi Client Arayüzü
6.4 Data Poisoning Simülasyonu
Bu özellik, makalemin etik odak noktasıdır. Admin panelinden saldırı başlatıldığında, bazı botlar veya kasten yanlış işlem yapan kullanıcılar sisteme “yanlış gradyanlar” gönderir. Sunucu içeriği göremediği için bu yanlış verileri modele dahil eder ve global doğruluk oranının hızla çöktüğü görsel olarak gözlemlenir.
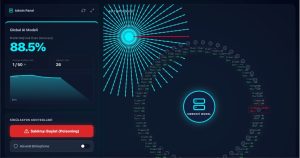
Şekil 4: Federated Learning Web Sitesi Doğruluk Düşüşü Arayüzü
6.5 Güvenli Toplama Mekanizmasının Simülasyonu
Saldırı anında “Güvenli Birleştirme” (Secure Aggregation) protokolü aktif edildiğinde, sistem anomali tespitine başlar. Güven skoru 50’nin altına düşen kullanıcıların verileri, merkezi model güncellenirken “birleştirme” dışı bırakılır. Böylece ağdaki kötü niyetli aktörler izole edilir ve modelin doğruluğu tekrar yükselmeye başlar.
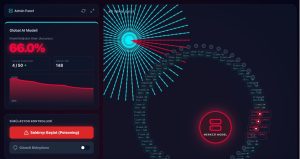
Şekil 5: Federated Learning Web Sitesi Doğruluk Birden Fazla Şüpheli Arayüzü
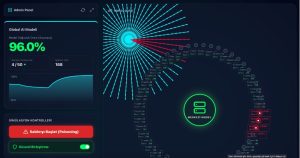
Şekil 6: Federated Learning Web Sitesi Doğruluk Güvenli Birleştirme Arayüzü
7. Bulgular ve Değerlendirme
7.1 Saldırı Durumunda Model Davranışı
Saldırıyı Başlat” butonuna bastığımda her şey bir anda değişti. Ağdaki kötü niyetli botlar sisteme yanlış veriler yağdırdı. Merkez sunucu gizlilik nedeniyle gelen verileri denetleyemedi. Bu durum model doğruluğunu (accuracy) hızla aşağı çekti. Başarı oranı %92 seviyesinden %40’a kadar geriledi. Sistem saniyeler içinde kararsız bir yapıya büründü. Görsel arayüzdeki “glitch” efektleri bu sapmayı somutlaştırdı. Bence bu durum, denetimsiz gizliliğin ne kadar riskli olduğunu gösteriyor.
7.2 Güvenli Toplama Sonrası Sonuçlar
Saldırı tüm hızıyla sürerken “Güvenli Birleştirme” protokolünü devreye aldığımda, sistemin savunma refleksi anında tepki verdi. İşin güzel tarafı şuydu: Sistem kullanıcıların özel verilerine hiç bakmadan, sadece istatistiksel sapmalar yapan ve güven skoru 50’nin altına düşen şüpheli düğümleri tek tek yakaladı. Bu “zehirli” düğümler ağdan izole edilir edilmez, o düşen grafiklerin tekrar yukarı tırmandığını ve sistemin yeniden güvenilir bir limana döndüğünü gördük.
7.3 Etik Açıdan Genel Değerlendirme
Elde ettiğim bu bulgular bence çok önemli bir şeyi kanıtlıyor: Federe Öğrenme sistemlerinde gizlilik tek başına yeterli değil. Sadece mahremiyete odaklanıp denetimi boş bırakırsanız, sistemi manipülasyonlara (data poisoning) karşı savunmasız bir hale getiriyorsunuz. Ama simülasyonda gösterdiğim gibi, mahremiyeti bozmadan sadece matematiksel sapmalar üzerinden bir denetim kurmak, sistemi hem “gizli” hem de “dürüst” tutabiliyor. Bu durum aslında yapay zeka etiğinde o çok tartışılan gizlilik-güvenlik dengesinin teknik çözümlerle pekala kurulabileceğini gösteriyor.
8. Sonuç
Bu çalışmada Federe Öğrenme’nin bir yan etkisini gördüm. Mahremiyet aslında ciddi bir “denetlenemezlik” sorunu yaratıyor. Bu durumu kendi hazırladığım simülasyonla ortaya koydum. Gizlilik uğruna veriye bakamamak sistemi savunmasız bırakıyor. Zehirli saldırılar modeli kolayca hedef alabiliyor. Ancak geliştirdiğim yöntemlerle sistemin dürüstlüğünü kurtarmayı başardık. Güven Skoru ve Anomali Tespiti burada kilit rol oynadı. Kimsenin özel verisine dokunmadan güvenliği sağlamak mümkün. Bence işin özeti çok net. Doğru yaklaşımlarla gizlilik ve güvenlik beraber yürüyebilir.
9. Kısaca Özet
Bu makalede Federe Öğrenme sistemlerini hem teorik hem uygulamalı ele aldım. Gizlilik ve güveniliği inceledim. Yaptığım web tabanlı simülasyon sayesinde bazı sonuçlara ulaştık. Öncelikle kullanıcı verilerini gizli tutmak etik bir zorunluluktur. Ancak bu mesele kötü niyetli kişilere bazen zemin hazırlayabiliyor. Özellikle sisteme yanlış bilgiler sızdırmak (data poisoning) büyük bir risk oluşturuyor.
Buna rağmen simülasyonda uyguladığım protokol oldukça başarılı oldu. “Güvenli Birleştirme” yöntemi verilerin içeriğine hiç bakmadan saldırıları durdurdu. Sadece istatistiksel sapmaları takip ederek sistemi korumayı başardı. Sonuç olarak mahremiyet ve güvenlik birbirine engel olmak zorunda değildir. Aksine doğru algoritmalarla her ikisini de sağlamak mümkündür. Hem kullanıcının özel hayatı korunabilir hem de sistem dürüst kalabilir. Gelecekte bu tür hibrit modellerin kullanılması çok kritik olacaktır. Bu sayede bilişim etiği açısından daha güvenli dijital dünyalar kurabiliriz.
10. Kaynakça
Bhagoji, A. N., Chakraborty, S., Mittal, P. ve Calo, S. (2019). Analyzing federated learning through an adversarial lens. Proceedings of the 36th International Conference on Machine Learning (ICML), 634-643. https://proceedings.mlr.press/v97/bhagoji19a.html
Bonawitz, K., Ivanov, V., Kreuter, B., Marcedone, A., McMahan, H. B., Patel, S., Ramage, D., Segal, A. ve Seth, K. (2017). Practical secure aggregation for privacy-preserving machine learning. Proceedings of the 2017 ACM SIGSAC Conference on Computer and Communications Security, 1175-1191. https://dl.acm.org/doi/10.1145/3133956.3133982
Kairouz, P., McMahan, H. B., Avent, B., Bellet, A., Bennis, M., Bhagoji, A. N. ve ark. (2021). Advances and open problems in federated learning. Foundations and Trends® in Machine Learning, 14(1–2), 1-210. https://www.emerald.com/ftmal/article/14/1-2/1/1332154/Advances-and-Open-Problems-in-Federated-Learning
McMahan, B., Moore, E., Ramage, D., Hampson, S. ve Arcas, B. A. (2017). Communication-efficient learning of deep networks from decentralized data. Proceedings of the 20th International Conference on Artificial Intelligence and Statistics (AISTATS), 1273-1282. https://proceedings.mlr.press/v54/mcmahan17a.html
Mothukuri, J., Parizi, R. M., Pouriyeh, S., Huang, Y., Dehghantanha, A. ve Srivastava, G. (2021). A survey on security and privacy of federated learning. Future Generation Computer Systems, 115, 619-640. https://www.sciencedirect.com/science/article/pii/S0167739X20329848
MarcT0K. (y.y.). Centralized federated learning protocol [Görsel]. Wikimedia Commons. Erişim adresi: https://commons.wikimedia.org/wiki/File:Centralized_federated_learning_protocol.png CC BY-SA 4.0 lisansı ile kullanılmıştır.
EKLER
EK-1: İntihal
Makale 13.05.2026 tarihinde https://plagiarismdetector.net/ adresinde iki parça olarak benzerlik incelemesinden geçmiştir.
1: 2% Plagiarism – 98% Unique
2: 2% Plagiarism – 98% Unique
EK-2: AI Detector
Makale 13.05.2026 tarihinde https://copyleaks.com/tr/ai-content-detector adresinde yapay zeka içerik incelemesinden geçmiştir.
1: 20.2% AI Text – %79.8 Human Text

Bu eser Esmanur Dursunbek tarafından Creative Commons Atıf-AynıLisanslaPaylaş 4.0 Uluslararası Lisansı ile lisanslanmıştır.
Marmara Üniversitesi Bilgisayar ve Öğretim Teknolojileri Eğitimi (BÖTE) bölümünde lisans eğitimime devam eden, yazılım geliştirme dünyasında hevesli bir geliştiriciyim. Akademik eğitimim boyunca edindiğim pedagojik ve teknolojik altyapıyı, profesyonel yazılım dünyasının dinamikleriyle harmanlayarak sürdürülebilir çözümler üretmeyi hedefliyorum. Kariyerimin merkezinde yer alan kodlamayla, karmaşık mantıksal süreçleri verimli algoritmalara dönüştürmek en büyük motivasyon kaynağımı oluşturmaktadır.
Profesyonel kariyerimde yaklaşık bir yıldır Conforcus bünyesinde Junior ABAP Geliştirici olarak görev yapmaktayım. Bu bir yıllık süreçte, SAP sistemlerinin mimarisi, kurumsal iş süreçlerinin dijitalleştirilmesi ve büyük ölçekli kurumsal kaynak planlama projelerinde aktif rol alarak önemli bir deneyim kazandım. ABAP dilinde yazdığım her satır kodda, sistem performansını optimize etmeyi ve kurumsal güvenliği en üst düzeyde tutmayı ilke edindim. Kodlama sadece benim için bir iş tanımı değil, aynı zamanda sürekli kendimi güncellediğim ve yeni teknolojileri keşfettiğim bir öğrenme yolculuğudur.
Gelecek hedeflerim doğrultusunda, kurumsal yazılım mimarilerine olan ilgimi veri odaklı yaklaşımlarla birleştirerek dijital dönüşüm projelerinde öncü roller üstlenmeyi amaçlıyorum. Marmara Üniversitesi’nde aldığım nitelikli eğitim ve Conforcus’taki profesyonel saha tecrübemle, teknoloji dünyasının etik ve güvenlik standartlarına sadık kalarak yenilikçi projeler geliştirmeye devam ediyorum. Sürekli öğrenen ve üreten biri olarak, yazılım ekosistemine değer katma yolunda kararlılıkla ilerlemekteyim.


{kind=link}